Memorias RAM externas en MCS51 (8051/8052)
Este artículo sirve también para todos microcontroladores derivados de los 8052 (AT89C52, AT89S52, AT89S8253, entre otros…)
Al leer de una posición de memoria externa (movx a, @dptr), el microcontrolador hace lo siguiente:
- Pone en P0 la parte baja de la dirección (DPL)
- Hace un pulso en el pin 30 (ALE)
- Pone en P2 la parte alta de la dirección (DPH)
- Hace un pulso en P3_7 (RD)
- Lee de P0 el dato, lo guarda en el acumulador
Al escribir a una posición de memoria externa (movx @dptr, a), el microcontrolador hace algo similar:
- Pone en P0 la parte baja de la dirección (DPL)
- Hace un pulso en el pin 30 (ALE)
- Pone en P2 la parte alta de la dirección
- Pone en P0 lo que hay en el acumulador
- Hace un pulso en P3_6 (WR)
Como P0 se usa tanto como bus de datos como parte baja del bus de direcciones (este método se llama multiplexado de bus de datos y dirección), es necesario agregar un latch de 8 valores, para guardar la parte baja de la dirección.
El circuito por lo tanto queda así:
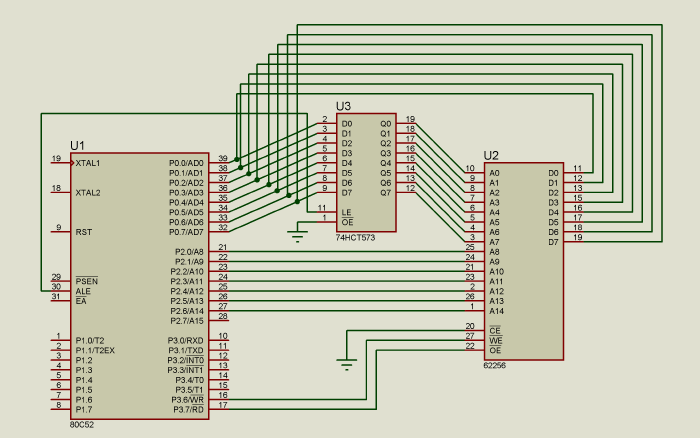
Como la memoria es de acceso aleatorio, no importa si conectamos un pin del bus de dirección a cualquier pin de address, siempre que estén todas conectadas funcionará, lo único que cambiará será el espacio físico de la memoria.
Por lo tanto, es posible hacer el circuito impreso en una capa y con pocos saltos, de la siguiente manera:
Descargar circuito impreso editable en Proteus
Limpiando un buffer en memoria externa (forma optimizada)
Suponiendo que se tiene un buffer de 1024 bytes, en la dirección externa 0, en un 8052 corriendo a 24MHz
La forma más facil que a uno le viene a la mente para borrar ese buffer sería usar cuatro loops, cada uno limpiaría 256 bytes:
mov dptr, #0 ;Donde empieza el buffer
mov a, #0xAA ;Valor con que se lo quiere llenar
mov r0, #0
lp1:movx @dptr, a
inc dptr
djnz r0, lp1
mov r0, #0
lp2:movx @dptr, a
inc dptr
djnz r0, lp2
mov r0, #0
lp3:movx @dptr, a
inc dptr
djnz r0, lp3
mov r0, #0
lp4:movx @dptr, a
inc dptr
djnz r0, lp4
Esta solución tarda 3076,5 uS (medido con el simulador de Keil uVision).
Para algunas aplicaciones críticas es demasiado tiempo… por eso necesitamos optimizarlo.
La primera optimización que se puede hacer es sacar los 4 loops y reemplazarlos por uno solo:
mov dptr, #0
mov a, #0xAA
mov r0, #0
lp1:movx @dptr, a
inc dptr
movx @dptr, a
inc dptr
movx @dptr, a
inc dptr
movx @dptr, a
inc dptr
djnz r0, lp1
Esto, además de reducir el tamaño en código aumenta la velocidad de ejecución, que pasó a 2307uS, una mejora del 30%.
Es posible reducirlo más todavía, haciendo uso de una instrucción no tan usada, movx @r0, a, que hace lo mismo que dptr pero solo con un registro de 8 bits, usando P2 como la parte alta de DPTR.
mov a, #0xAA
mov r0, #0
lp1:
mov p2, #0
movx @r0, a
inc p2
movx @r0, a
inc p2
movx @r0, a
inc p2
movx @r0, a
djnz r0, lp1
Ahora tarda unicamente 1922 uS.
Desentrelazando el loop (es decir, reduciendo la frecuencia entre djnz agregando más lineas que afecten datos) es posible llegar a 1858uS (x2) o 1826 (x4).
Esta forma logra hacer 1603uS! Casi la mitad que el primer método!
mov a, #0xAA
mov r0, #0
mov p2, #0
lp1:
movx @r0, a ;P2 = 0
inc p2
movx @r0, a ;P2 = 1
inc p2
movx @r0, a ;P2 = 2
inc p2
movx @r0, a ;P2 = 3
dec r0
movx @r0, a ;P2 = 3
dec p2
movx @r0, a ;P2 = 2
dec p2
movx @r0, a ;P2 = 1
dec p2
movx @r0, a ;P2 = 0
djnz r0, lp1
Para analizar el rendimiento absoluto, es posible ver que los movx tardan 1uS, y los inc 0.5uS, se podría decir que para que sea 100% óptimo tendría que tardar 1536uS para borrar el buffer… Teniendo en cuenta que este método tarda 1603uS, es 93% eficiente, bastante bien para un par de optimizaciones relativamente sencillas.
La idea de optimizar es encontrar el balance entre uso de memoria extra (tanto de código como de datos) y la complejidad del algoritmo.